Workflow+ Architect
Herausforderung
Die büro+ ERP-Benutzer von AlphaCom mussten Workflow+-Automatisierungsskripte schreiben – eine Aufgabe, die Kenntnisse von Hunderten proprietärer Befehle mit spezialisierter Syntax erfordert. Die Lernkurve war steil, die Skriptentwicklung dauerte Stunden oder Tage, und Fehler waren häufig.
Lösung
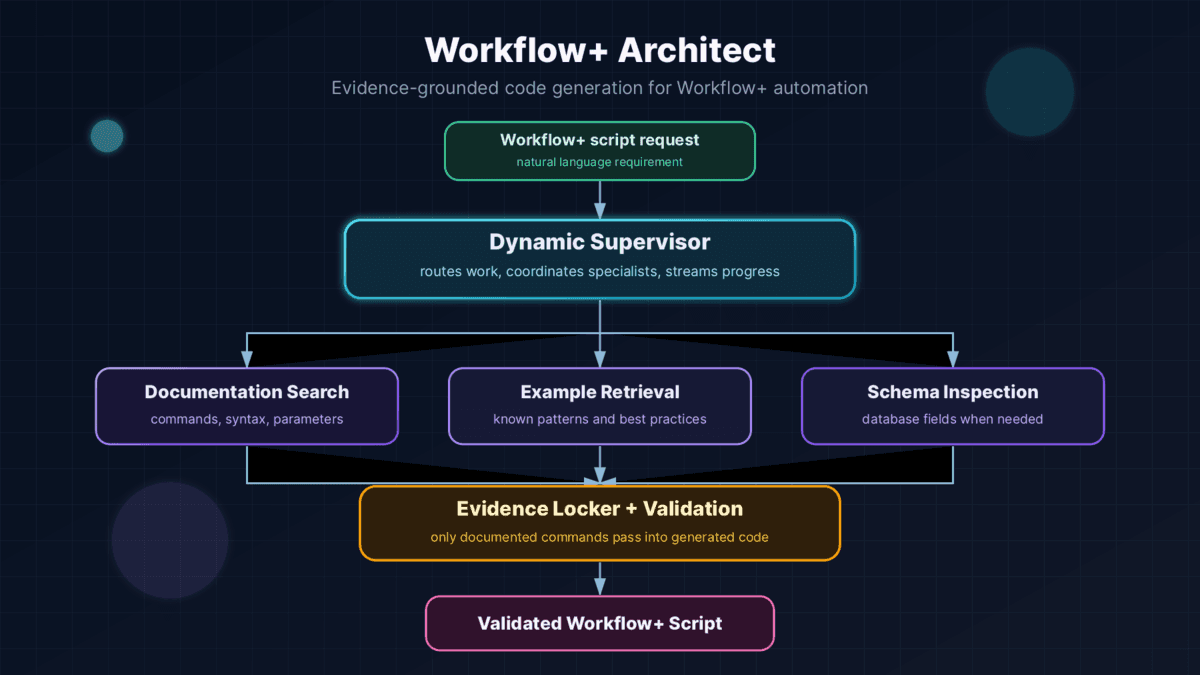
Ich konzipierte und entwickelte Workflow+ Architect, ein Multi-Agenten-KI-System, bei dem ein dynamischer Supervisor spezialisierte Worker-Agenten parallel orchestriert. Das System durchsucht Dokumentationen, ruft Musterbeispiele ab und inspiziert Datenbankschemas bei Bedarf. Eine Evidence-Only-Validierungsschicht stellt sicher, dass generierter Code nur Befehle verwenden kann, die durch Dokumentationssuche verifiziert wurden, und fängt Halluzinationen ab, bevor sie den Benutzer erreichen. Pinned File State und kontextverankertes Editieren lösen die hartnäckigen Probleme von LLM-Gedächtnisdrift und Zeilennummer-Fehlzählung.
Ergebnis
Die Skriptgenerierung sank von Stunden auf Minuten. Die optimierte Sucharchitektur reduziert LLM-API-Aufrufe signifikant durch Caching und Wiederverwendung von Suchergebnissen. Das Evidence-Validierungssystem fängt Halluzinationen ab, indem es nur Befehle zulässt, die in der Dokumentation gefunden wurden. Eine kontinuierliche Lernpipeline erfasst Benutzerkorrekturen und extrahiert verallgemeinerbare Muster, sodass sich das System mit der Nutzung verbessert. Das Projekt läuft in Produktion mit vollständiger Observability via OpenTelemetry, Prometheus und Grafana-Dashboards.
Wichtige Highlights
Multi-Agenten-Orchestrierung
Ein dynamischer Supervisor analysiert Anfragen und spawnt spezialisierte Worker parallel – Dokumentationssuche, Beispielabruf und Schema-Inspektion – und synthetisiert Ergebnisse zu kohärenten Antworten.
Intelligente Sucharchitektur
Zweischichtige Suche kombiniert BM25-Volltext- und Vektor-Embeddings mit Reciprocal Rank Fusion. HyDE generiert hypothetische Dokumentation für besseren Recall, während gestufte Eskalation und ein 1000-Einträge-Embedding-Cache API-Aufrufe um ~50% reduzieren.
Semantische Selbstverifikation
Ein kleines LLM extrahiert Befehlsaufrufe semantisch aus generiertem Code – versteht Struktur statt Pattern-Matching. Erkennt ~80% halluzinierter Befehle, die Regex übersehen würde.
Kontextverankertes Editieren
Eliminiert Zeilennummer-Drift durch die Verwendung von Codeblock-Ankern für chirurgische Bearbeitungen. Der Agent liefert Ziel- und Ersetzungsblöcke statt Zeilennummern für präzise Modifikationen.
Pinned File State
Die physische Skriptdatei wird bei jedem Turn von der Festplatte gelesen und löst das LLM-Gedächtnisproblem. Die KI verlässt sich nie auf veralteten Konversationsspeicher für den Code-Zustand.
Echtzeit-Streaming
SignalR WebSocket liefert Tokens während der Generierung mit Phasen-Fortschrittsereignissen. Ein Streaming-Filter trennt internes Reasoning von der Benutzerausgabe – saubere Antworten mit voller Debugging-Fähigkeit.
Kontinuierliches Lernen
Benutzerkorrekturen durchlaufen eine Pipeline: Erfassung, Validierung, Musterextraktion und Konfidenz-Scoring. Das System ruft relevante Muster für zukünftige Abfragen via semantischer Suche ab.
Resiliente Architektur
Vollständiges Circuit-Breaker-Pattern mit Zustandsübergängen und Fehlertracking. Per-Endpoint-Rate-Limiting mit mehreren Algorithmen, LangSmith-Tracing für Debugging und adaptives Sampling unter Last.
Kundenstimme
“Mit Workflow+ Architect haben wir einen KI-gestützten Programmierassistenten für unsere Workflow+-Skriptsprache entwickelt. Die Lösung unterstützt Anwender dabei, Scripts schneller zu erstellen, bestehende Abläufe nachzuvollziehen und relevantes Workflow+-, büro+- und GraphQL-Wissen direkt im Entwicklungsprozess zu nutzen. Tobias Fankhauser hat uns dabei geholfen, ein technisch anspruchsvolles Thema in eine praxistaugliche Produkterweiterung zu übersetzen.”