Sind 'KI-Halluzinationen' unvermeidlich? Wie RAG Vertrauen im Geschäft schafft

Sie haben wahrscheinlich die Geschichten gehört: Large Language Models (LLMs) wie ChatGPT geben selbstbewusst falsche Fakten an, erfinden Quellen oder weichen komplett vom Thema ab. Dieses Phänomen, oft als „KI-Halluzination“ bezeichnet, ist ein grosses Anliegen für Unternehmen, die KI für kritische Aufgaben nutzen möchten. Wenn Sie dem Output der KI nicht vertrauen können, wie können Sie sich dann darauf verlassen?
Obwohl kein komplexes System perfekt ist, ist das Narrativ, dass Halluzinationen einfach ein unvermeidlicher Fluch von LLMs sind, nicht ganz zutreffend – insbesondere wenn sie im Geschäftskontext korrekt angewendet werden. Bei Fanktank bauen wir KI-Lösungen, die auf Zuverlässigkeit ausgelegt sind, und eine Schlüsseltechnik, die wir einsetzen, ist **Retrieval-Augmented Generation (RAG)**.
Was verursacht KI-Halluzinationen?
LLMs sind hochentwickelte Mustererkennungsmaschinen, die auf riesigen Mengen an Textdaten trainiert wurden. Sie zeichnen sich dadurch aus, flüssigen, menschenähnlichen Text basierend auf den Mustern zu generieren, die sie gelernt haben. Jedoch:
- **Sie „kennen“ keine Fakten:** Sie sagen das nächstwahrscheinlichste Wort basierend auf ihren Trainingsdaten voraus, nicht notwendigerweise basierend auf faktischer Korrektheit in der realen Welt ([IBM, 2024](https://www.ibm.com/think/topics/ai-hallucinations)).
- **Veraltetes Wissen:** Ihre Trainingsdaten haben einen Stichtag. Sie sind sich Ereignissen oder Informationen, die nach diesem Datum erstellt wurden, nicht bewusst, es sei denn, sie werden spezifisch aktualisiert oder erhalten neuen Kontext.
- **Mehrdeutige Prompts:** Vage oder unklare Fragen können das Modell auf statistisch wahrscheinliche, aber faktisch falsche Pfade führen ([Lakera, 2024](https://www.lakera.ai/blog/guide-to-hallucinations-in-large-language-models)).
- **Eigenheiten des Reinforcement Learning:** Der Prozess, der verwendet wird, um Modelle hilfreich und harmlos zu machen, kann manchmal unbeabsichtigt plausibel klingende, aber unwahre Aussagen fördern.
Für allgemeine kreative Aufgaben mögen gelegentliche Ungenauigkeiten akzeptabel sein. Für Geschäftsanwendungen – Kundensupport, interner Wissenszugriff, Datenanalyse – sind sie oft Dealbreaker.
Hier kommt RAG ins Spiel: KI in Ihrer Realität verankern
RAG verändert grundlegend, wie ein LLM Antworten generiert, indem es gezwungen wird, sich auf spezifische, verifizierte Informationen zu verlassen, die *zum Zeitpunkt der Anfrage bereitgestellt werden*. Anstatt sich ausschliesslich auf seine riesigen (aber potenziell fehlerhaften oder veralteten) internen Trainingsdaten zu verlassen, funktioniert der Prozess wie folgt:
- **Retrieve (Abrufen):** Wenn eine Frage gestellt wird, durchsucht das RAG-System *Ihre* definierte, aktuelle Wissensdatenbank (Firmendokumente, Produkthandbücher, Datenbanken) nach relevanten Informationsschnipseln.
- **Augment (Anreichern):** Diese abgerufenen Snippets („Kontext“) werden dem Prompt hinzugefügt, der dem LLM gegeben wird.
- **Generate (Generieren – Verankert):** Das LLM wird explizit angewiesen: *"Beantworte die Frage des Benutzers NUR basierend auf dem bereitgestellten Kontext."* ([AWS, 2024](https://aws.amazon.com/what-is/retrieval-augmented-generation/))
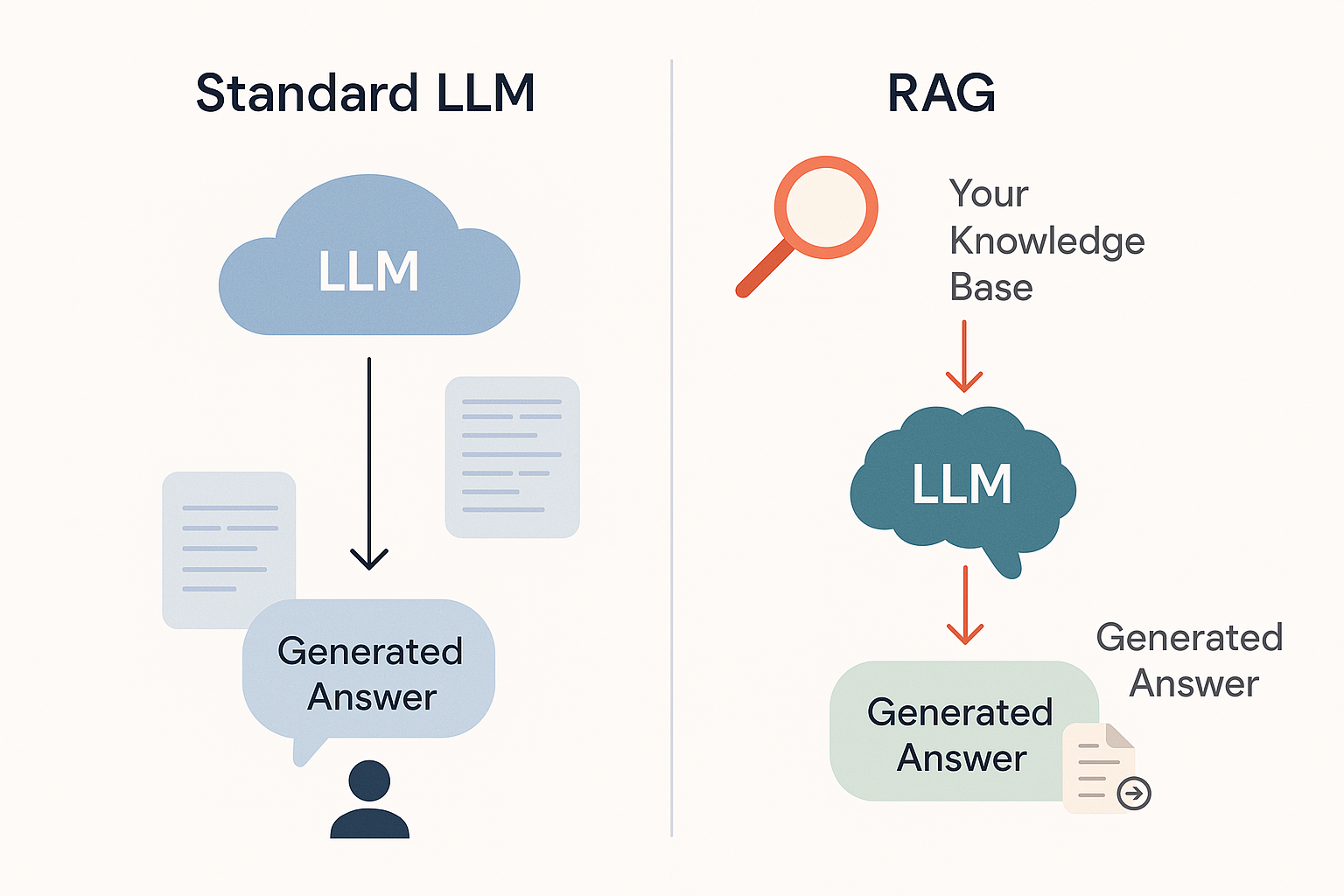
Dieser „Grounding“-Mechanismus reduziert Halluzinationen drastisch, weil:
- **Antworten aus Ihren Daten stammen:** Das LLM rät nicht; es synthetisiert Informationen aus Quellen, die *Sie* kontrollieren und denen Sie vertrauen ([Moveworks, 2024](https://www.moveworks.com/us/en/resources/ai-terms-glossary/retrieval-augmented-generation)).
- **Wissen aktuell ist:** Das RAG-System bezieht sich auf Ihre neuesten Dokumente, nicht auf alte Trainingsdaten.
- **Überprüfbarkeit:** Gute RAG-Systeme liefern Zitate, die Antworten mit den spezifischen Quelldokumenten verknüpfen, sodass Benutzer die Informationen überprüfen können ([SemiEngineering, 2024](https://semiengineering.com/rag-enabled-ai-stops-hallucinations-adds-sources/)).
Ist RAG narrensicher?
Obwohl RAG die Zuverlässigkeit erheblich verbessert, bleiben einige Nuancen:
- **Retrieval-Qualität:** Das System muss den *richtigen* Kontext abrufen. Ein schlechter Retrieval kann immer noch zu ungenauen Antworten führen, auch wenn sie *auf dem abgerufenen Kontext* basieren. Dies erfordert sorgfältige Indexierungs- und Suchstrategien.
- **Kontextintegration:** Das LLM muss Informationen aus potenziell mehreren abgerufenen Snippets korrekt synthetisieren, ohne Fehlinterpretationen.
- **Quellenqualität:** Die Genauigkeit des RAG-Systems hängt letztlich von der Genauigkeit und Qualität der zugrunde liegenden Dokumente in Ihrer Wissensdatenbank ab. (Garbage in, garbage out gilt immer noch). ([Stanford HAI, 2024](https://hai.stanford.edu/news/ai-trial-legal-models-hallucinate-1-out-6-queries))
Aufbau vertrauenswürdiger KI mit Fanktank
Bei Fanktank ist das Design effektiver RAG-Systeme eine Kernkompetenz. Wir konzentrieren uns auf:
- Optimierung des Retrieval-Prozesses, um die relevantesten Informationen zu finden.
- Erstellung präziser Prompts für das LLM, um eine verankerte Generierung sicherzustellen.
- Implementierung robuster Bewertungsmethoden zur Messung von Genauigkeit und Relevanz.
- Sicherstellung, dass die zugrunde liegende Wissensdatenbank gut strukturiert und gepflegt ist.
Erfahren Sie mehr über unseren Ansatz in unserem [Service für intelligente Wissenssysteme](/de/services/knowledge-systems).
Fazit: Von unzuverlässigen Vermutungen zum vertrauenswürdigen Assistenten
KI-Halluzinationen sind ein berechtigtes Anliegen, aber sie sind kein unüberwindbares Hindernis für die Geschäftsanwendung. Durch die Implementierung von Techniken wie RAG können wir leistungsstarke LLMs in faktischen, unternehmensspezifischen Daten verankern und sie von potenziell unzuverlässigen Orakeln in vertrauenswürdige, sachkundige Assistenten verwandeln.
**Bereit, einen KI-Assistenten zu bauen, auf den sich Ihr Team und Ihre Kunden verlassen können? Lassen Sie uns besprechen, wie RAG fundierte, genaue Antworten aus Ihren eigenen Daten liefern kann.**
[Intelligente Wissenssysteme entdecken](/de/services/knowledge-systems) oder [Beratungsgespräch buchen](/de/contact)
Referenzen
- [IBM, 2024] ["What Are AI Hallucinations?"](https://www.ibm.com/think/topics/ai-hallucinations), IBM. *(Erklärt die Ursachen von KI-Halluzinationen, einschliesslich Overfitting und Ungenauigkeiten in Trainingsdaten.)*
- [Lakera, 2024] ["Guide to Hallucinations in Large Language Models"](https://www.lakera.ai/blog/guide-to-hallucinations-in-large-language-models), Lakera. *(Schlüsselt Quellen von Halluzinationen auf und wie Modelle auf Robustheit getestet werden können.)*
- [AWS, 2024] ["What is RAG? - Retrieval-Augmented Generation AI Explained"](https://aws.amazon.com/what-is/retrieval-augmented-generation/), AWS. *(Beschreibt, wie RAG LLM-Outputs durch Referenzierung autoritativer externer Wissensdatenbanken optimiert.)*
- [Moveworks, 2024] ["What is Retrieval Augmented Generation (RAG)?"](https://www.moveworks.com/us/en/resources/ai-terms-glossary/retrieval-augmented-generation), Moveworks. *(Hebt hervor, wie RAG KI-Ausgaben in faktischen Daten verankert und so das Risiko von Fehlinformationen reduziert.)*
- [SemiEngineering, 2024] ["RAG-Enabled AI Stops Hallucinations, Adds Sources"](https://semiengineering.com/rag-enabled-ai-stops-hallucinations-adds-sources/), SemiEngineering. *(Diskutiert, wie RAG-Modelle die Antwortgenauigkeit durch Daten-Chunking und Quellenangaben verbessern.)*
- [Stanford HAI, 2024] ["AI on Trial: Legal Models Hallucinate in 1 out of 6 (or More) Queries"](https://hai.stanford.edu/news/ai-trial-legal-models-hallucinate-1-out-6-queries), Stanford HAI. *(Veröffentlicht 4. Juni 2024; diskutiert die Häufigkeit von Halluzinationen in KI-Tools für juristische Recherchen.)*