Datenvorbereitung für eine erfolgreiche RAG-Implementierung: Eine Checkliste

Retrieval-Augmented Generation (RAG)-Systeme versprechen Grosses bei der Erschliessung von Unternehmenswissen. Indem sie Benutzern ermöglichen, interne Dokumente mittels natürlicher Sprache abzufragen, steigern sie Produktivität und Entscheidungsfindung. Allerdings gilt hier das Sprichwort „Müll rein, Müll raus“ in hohem Masse. Die Leistung und Zuverlässigkeit Ihres RAG-Systems hängen stark von der Qualität und Vorbereitung der Quelldokumente ab, mit denen Sie es füttern ([deepset, 2024](https://www.deepset.ai/blog/preprocessing-rag), [outerbounds, 2023](https://outerbounds.com/blog/retrieval-augmented-generation)).
Basierend auf unserer Erfahrung beim Aufbau von [intelligenten Wissenssystemen](/de/services/knowledge-systems) bei Fanktank ist die korrekte Vorbereitung Ihrer Daten *vor* der Implementierung entscheidend. Wird dieser Schritt überstürzt, führt dies oft zu schlechter Retrieval-Genauigkeit, irrelevanten Antworten und Benutzerfrustration ([orkes.io, 2025](https://orkes.io/blog/rag-best-practices/)).
Nutzen Sie diese Checkliste als praktischen Leitfaden, um Ihren Dokumentenkorpus für eine erfolgreiche RAG-Implementierung vorzubereiten.
Die RAG-Datenvorbereitungs-Checkliste
**Phase 1: Sammlung & Kuration**
- **[ ] Relevante Quellen identifizieren:** Bestimmen Sie genau, welche Dokumente, Websites, Datenbanken oder andere Ressourcen das Wissen enthalten, auf das das RAG-System zugreifen soll. Seien Sie spezifisch. (z. B. HR-Richtlinienordner, Produkthandbücher v3.0+, Support-Ticket-Wissensdatenbank).
- **[ ] Formate konsolidieren:** Konvertieren Sie Dokumente nach Möglichkeit in konsistente, maschinenlesbare Formate. PDFs sind üblich, stellen Sie jedoch sicher, dass sie auswählbaren Text enthalten, nicht nur Bilder. Strukturierte Formate wie Markdown oder HTML sind oft genauer zu parsen als komplexe Word-Dokumente oder Präsentationen ([Microsoft, 2024](https://learn.microsoft.com/en-us/answers/questions/2034520/azure-ai-search-document-preprocessing)).
- **[ ] Zugänglichkeit sicherstellen:** Bestätigen Sie, dass Sie über die technischen Mittel und Berechtigungen verfügen, um auf alle identifizierten Quellen zuzugreifen und diese zu verarbeiten.
- **[ ] Duplikate & veraltete Informationen entfernen:** Bereinigen Sie Ihren Korpus. Entfernen Sie exakte Dateiduplikate. Identifizieren und archivieren oder kennzeichnen Sie veraltete Versionen von Dokumenten deutlich, um zu vermeiden, dass widersprüchliche oder falsche Informationen abgerufen werden ([Encord, 2023](https://encord.com/blog/data-cleaning-data-preprocessing/)).
- **[ ] Inhaltsgenauigkeit überprüfen:** Während RAG Antworten verankert, stützt es sich auf die Korrektheit des Quellmaterials. Führen Sie eine übergeordnete Überprüfung durch oder identifizieren Sie Fachexperten, die die Genauigkeit kritischer Dokumente bestätigen können ([Intel, 2024](https://medium.com/intel-tech/four-data-cleaning-techniques-to-improve-large-language-model-llm-performance-77bee9003625)).
**Phase 2: Bereinigung & Vorverarbeitung**
- **[ ] Gescannte Dokumente behandeln (OCR):** Wenn Sie bildbasierte PDFs oder Scans haben, wenden Sie Optical Character Recognition (OCR) an, um den Text zu extrahieren. *Überprüfen Sie die OCR-Qualität entscheidend* – Fehler hier wirken sich direkt auf das Verständnis der KI aus ([SearchBlox, 2024](https://medium.com/searchblox/how-to-process-documents-for-rag-retrieval-augmented-generation-chatbots-616c18e70a85)).
- **[ ] Unerwünschte Elemente entfernen:** Bereinigen Sie Dokumente, indem Sie irrelevante Kopf- und Fusszeilen, Seitenzahlen, umfangreiche Standardtexte oder Navigationsmenüs (aus Web-Scrapes) entfernen, die keinen semantischen Mehrwert für den Abruf bieten ([lakeFS, 2024](https://lakefs.io/blog/data-preprocessing-in-machine-learning/)).
- **[ ] Komplexe Layouts adressieren:** Erwägen Sie für Dokumente mit Tabellen, mehrspaltigen Layouts oder komplexen Abbildungen spezielle Parsing-Tools oder -Strategien. Eine einfache Textextraktion könnte den Inhalt durcheinanderbringen und den Abruf beeinträchtigen. Manchmal kann die Konvertierung von Tabellen in Markdown oder die Beschreibung von Abbildungen in Text helfen ([Akash, 2024](https://akash97715.medium.com/data-preparation-for-rag-part-1-b8bee1130115)).
- **[ ] Zeichenkodierung prüfen:** Stellen Sie sicher, dass alle Texte eine konsistente Kodierung verwenden (UTF-8 ist Standard), um Verarbeitungsfehler zu vermeiden.
**Phase 3: Strukturierung & Chunking-Strategie**
- **[ ] Metadaten definieren:** Identifizieren Sie nützliche Metadaten für jedes Dokument (z. B. Titel, Autor, Erstellungsdatum, letztes Aktualisierungsdatum, Quell-URL, Abteilung, zugehöriges Produkt). Diese Metadaten können neben den Text-Chunks gespeichert und zum Filtern während des Abrufs verwendet werden ([Snowflake, 2024](https://www.snowflake.com/en/blog/streamline-rag-document-preprocessing/)).
- **[ ] Optimale Chunk-Grösse bestimmen:** Dies ist kritisch und erfordert oft Experimente. Chunks müssen klein genug sein, um semantisch fokussiert zu sein, aber gross genug, um ausreichenden Kontext zu enthalten. Übliche Grössen liegen zwischen 100 und 500 Tokens ([TiDB, 2024](https://www.pingcap.com/article/building-a-rag-application-from-scratch-a-beginners-guide/)).
- **[ ] Chunking-Strategie wählen:**
- *Feste Grösse:* Einfach, kann aber Sätze oder Ideen ungeschickt trennen.
- *Satzbasiert:* Bessere semantische Kohärenz (z. B. unter Verwendung von Bibliotheken wie NLTK oder spaCy).
- *Recursive Character Text Splitting:* Eine gängige LangChain-Technik, die versucht, Absätze/Sätze zusammenzuhalten.
- *Inhaltsbasiert:* Fortgeschrittenere Methoden, die basierend auf der Dokumentstruktur (Überschriften, Abschnitte) chunken ([Vipra Singh, 2024](https://medium.com/%40vipra_singh/building-llm-applications-data-preparation-part-2-b7306d224245)).
- **[ ] Chunk-Überlappung berücksichtigen:** Überlappende Chunks (z. B. das Teilen eines Satzes oder zweier an den Grenzen) können helfen sicherzustellen, dass der Kontext an den Trennpunkten nicht verloren geht, was potenziell den Abruf verbessert ([Big Cloud Country, 2024](https://www.bigcloudcountry.com/engineering-blog/planning-checklist-for-rag-projects-retrieval-augmented-generation)).
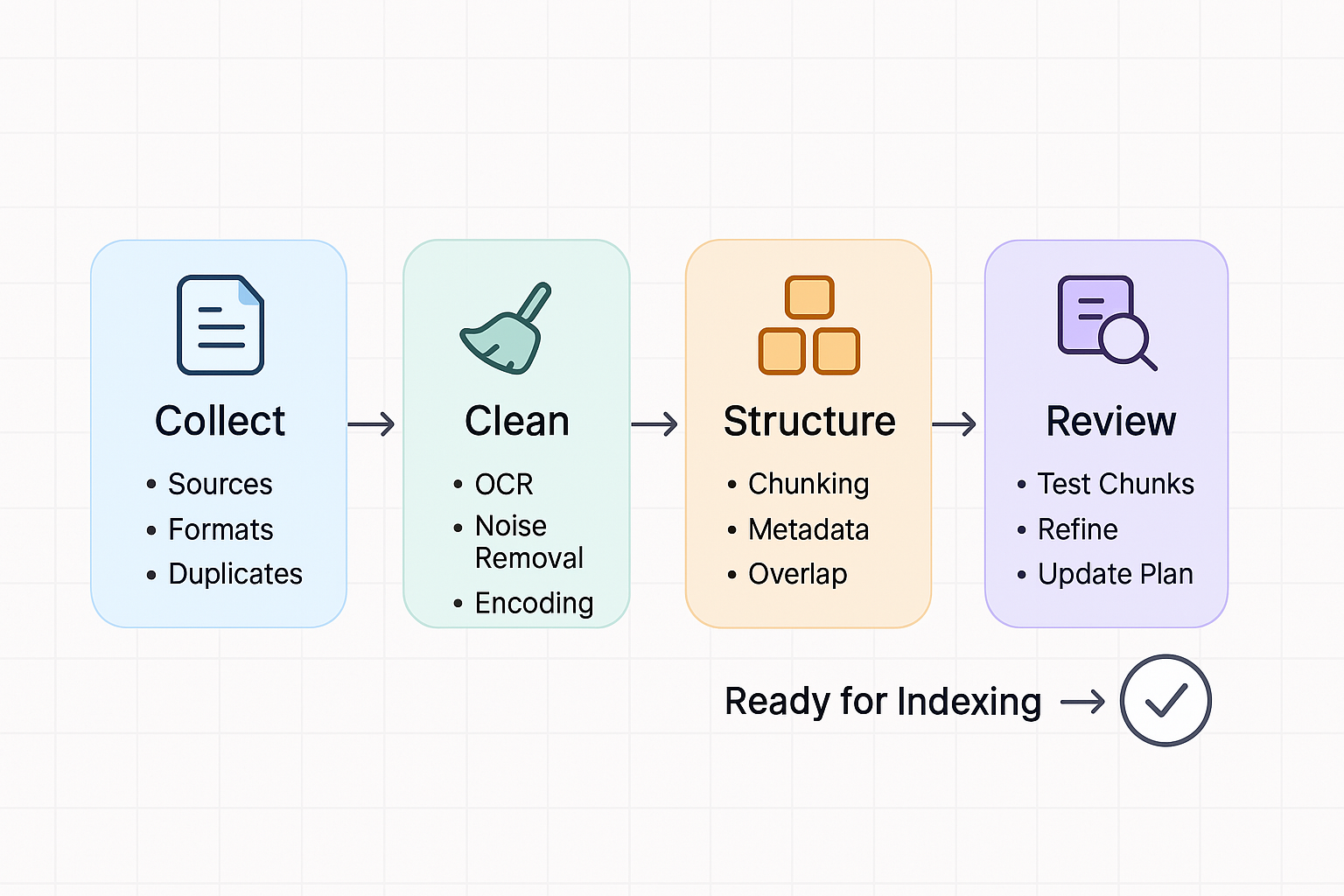
**Phase 4: Überprüfung & Iteration**
- **[ ] Verarbeitete Chunks stichprobenartig überprüfen:** Bevor Sie alles indizieren, überprüfen Sie eine Stichprobe der verarbeiteten Text-Chunks. Ergeben sie Sinn? Bleibt wichtiger Kontext erhalten? Wird irrelevantes Rauschen entfernt?
- **[ ] Retrieval testen:** Indizieren Sie eine Teilmenge von Dokumenten und testen Sie den Abruf mit repräsentativen Fragen. Werden die relevantesten Chunks zurückgegeben? Wenn nicht, überdenken Sie Ihre Bereinigungs- und Chunking-Strategie ([GPT-Trainer, 2025](https://gpt-trainer.com/blog/best%2Bpractices%2Bfor%2Bpreparing%2Btraining%2Bdata%2Bfor%2Brag)).
- **[ ] Updates planen:** Wie werden neue oder aktualisierte Dokumente dem System hinzugefügt? Definieren Sie einen Prozess für die laufende Wartung und Neuindizierung ([Keith Kueh, 2024](https://www.linkedin.com/pulse/best-practices-preparing-private-documents-retrieval-augmented-kueh-pbawc)).
Warum das wichtig ist
Eine gründliche Datenvorbereitung gewährleistet:
- **Höhere Retrieval-Genauigkeit:** Das System findet die *richtigen* Informationen.
- **Relevantere Antworten:** Das LLM erhält sauberen, fokussierten Kontext.
- **Reduzierte Halluzinationen:** Weniger irrelevantes Rauschen, das das LLM verwirrt.
- **Schnellere Implementierung:** Weniger Probleme während der Indizierungs- und Testphasen.
- **Bessere Benutzererfahrung:** Benutzer erhalten schnell zuverlässige Antworten.
Benötigen Sie Hilfe bei der Vorbereitung Ihrer Daten?
Die Datenvorbereitung kann zeitaufwändig sein, ist aber für den Erfolg von RAG unerlässlich. Fanktank unterstützt Kunden nicht nur beim Aufbau des KI-Systems, sondern auch bei der Strategieentwicklung und Durchführung der entscheidenden Datenvorbereitungsphase.
**Wenn Sie ein RAG-System in Betracht ziehen, aber unsicher sind, wie Sie Ihre Daten vorbereiten sollen, lassen Sie uns besprechen, wie wir helfen können.**
[Kostenloses Daten-Assessment Gespräch buchen](/de/contact)
Referenzen
- [Snowflake, 2024] ["Streamline RAG with New Document Preprocessing Features"](https://www.snowflake.com/en/blog/streamline-rag-document-preprocessing/), Snowflake. *(Behandelt Best Practices für die Konvertierung und Vorbereitung von Dokumenten für Chunking und Indexierung.)*
- [Akash, 2024] ["Data Preparation for RAG - Part 1"](https://akash97715.medium.com/data-preparation-for-rag-part-1-b8bee1130115), Medium. *(Beschreibt die Bedeutung der Dokumentenstandardisierung und Ingestionspipelines.)*
- [Big Cloud Country, 2024] ["Planning Checklist for RAG Projects"](https://www.bigcloudcountry.com/engineering-blog/planning-checklist-for-rag-projects-retrieval-augmented-generation), Rob Whelan. *(Bietet eine praktische Checkliste, die Chunking, Metadaten und Implementierung abdeckt.)*
- [Keith Kueh, 2024] ["Best Practices for Preparing Private Documents for RAG"](https://www.linkedin.com/pulse/best-practices-preparing-private-documents-retrieval-augmented-kueh-pbawc), LinkedIn. *(Skizziert Schritte für eine verantwortungsvolle Dokumentenverarbeitung.)*
- [Intel, 2024] ["Four Data Cleaning Techniques to Improve LLM Performance"](https://medium.com/intel-tech/four-data-cleaning-techniques-to-improve-large-language-model-llm-performance-77bee9003625), Medium. *(Konzentriert sich auf die Beseitigung von Rauschen und Inkonsistenzen vor der Aufnahme.)*
- [Encord, 2023] ["Mastering Data Cleaning & Preprocessing"](https://encord.com/blog/data-cleaning-data-preprocessing/), Encord. *(Erläutert grundlegende Reinigungsprozesse für strukturierte und unstrukturierte Daten.)*
- [deepset, 2024] ["The Role of Preprocessing in RAG"](https://www.deepset.ai/blog/preprocessing-rag), deepset. *(Diskutiert wichtige Vorverarbeitungsaufgaben wie Bereinigung, Chunking und Anreicherung.)*
- [orkes.io, 2025] ["Best Practices for Production-Scale RAG Systems"](https://orkes.io/blog/rag-best-practices/), Orkes. *(Konzentriert sich auf die Aufrechterhaltung der Retrieval-Präzision durch Dokumentenformatierung.)*
- [lakeFS, 2024] ["Data Preprocessing in ML"](https://lakefs.io/blog/data-preprocessing-in-machine-learning/), lakeFS. *(Listet Schritte zur Beseitigung von Redundanz und Verbesserung der Textkonsistenz auf.)*
- [SearchBlox, 2024] ["How to Process Documents for RAG"](https://medium.com/searchblox/how-to-process-documents-for-rag-retrieval-augmented-generation-chatbots-616c18e70a85), Medium. *(Hebt die Bedeutung von OCR und Bedenken hinsichtlich der Dokumentstruktur hervor.)*
- [Vipra Singh, 2024] ["LLM Applications: Data Prep Pt. 2"](https://medium.com/%40vipra_singh/building-llm-applications-data-preparation-part-2-b7306d224245), Medium. *(Erforscht verschiedene Chunking-Strategien und Überlappungstechniken.)*
- [outerbounds, 2023] ["Retrieval-Augmented Generation Guide"](https://outerbounds.com/blog/retrieval-augmented-generation), Outerbounds. *(Gibt Kontext zur Verankerung von LLMs durch Dokumentenanreicherung.)*
- [TiDB, 2024] ["Building a RAG App from Scratch"](https://www.pingcap.com/article/building-a-rag-application-from-scratch-a-beginners-guide/), TiDB. *(Behandelt Dokumentenvorbereitung, Chunking und Deployment-Workflows.)*
- [GPT-Trainer, 2025] ["Preparing Data for RAG"](https://gpt-trainer.com/blog/best%2Bpractices%2Bfor%2Bpreparing%2Btraining%2Bdata%2Bfor%2Brag), GPT-Trainer. *(Konzentriert sich auf frühes Testen und Iterieren basierend auf der Retrieval-Leistung.)*
- [Microsoft, 2024] ["Azure AI Search Document Preprocessing"](https://learn.microsoft.com/en-us/answers/questions/2034520/azure-ai-search-document-preprocessing), Microsoft. *(Erläutert Methoden zum Aufteilen langer Dokumente in Chunks mit Tools.)*