Preparing Your Data for a Successful RAG Implementation: A Checklist

Retrieval-Augmented Generation (RAG) systems hold immense promise for unlocking organisational knowledge. By allowing users to query internal documents using natural language, they boost productivity and decision-making. However, the adage "garbage in, garbage out" strongly applies. The performance and reliability of your RAG system heavily depend on the quality and preparation of the source documents you feed into it ([deepset, 2024](https://www.deepset.ai/blog/preprocessing-rag), [outerbounds, 2023](https://outerbounds.com/blog/retrieval-augmented-generation)).
Based on our experience building [Smart Knowledge Systems](/services/knowledge-systems) at Fanktank, preparing your data correctly *before* implementation is crucial. Rushing this step often leads to poor retrieval accuracy, irrelevant answers, and user frustration ([orkes.io, 2025](https://orkes.io/blog/rag-best-practices/)).
Use this checklist as a practical guide to prepare your document corpus for a successful RAG implementation.
The RAG Data Preparation Checklist
**Phase 1: Collection & Curation**
- **[ ] Identify Relevant Sources:** Determine exactly which documents, websites, databases, or other resources contain the knowledge the RAG system should access. Be specific. (e.g., HR Policy folder, Product Manuals v3.0+, Support Ticket Knowledge Base).
- **[ ] Consolidate Formats:** Where possible, convert documents to consistent, machine-readable formats. PDFs are common, but ensure they contain selectable text, not just images. Structured formats like Markdown or HTML are often easier to parse accurately than complex Word docs or presentations ([Microsoft, 2024](https://learn.microsoft.com/en-us/answers/questions/2034520/azure-ai-search-document-preprocessing)).
- **[ ] Ensure Accessibility:** Confirm you have the technical means and permissions to access and process all identified sources.
- **[ ] Remove Duplicates & Outdated Information:** Cleanse your corpus. Remove exact duplicate files. Identify and archive or clearly mark outdated versions of documents to avoid conflicting or incorrect information being retrieved ([Encord, 2023](https://encord.com/blog/data-cleaning-data-preprocessing/)).
- **[ ] Verify Content Accuracy:** While RAG grounds answers, it relies on the source material being correct. Perform a high-level review or identify subject matter experts who can vouch for the accuracy of critical documents ([Intel, 2024](https://medium.com/intel-tech/four-data-cleaning-techniques-to-improve-large-language-model-llm-performance-77bee9003625)).
**Phase 2: Cleaning & Pre-processing**
- **[ ] Handle Scanned Documents (OCR):** If you have image-based PDFs or scans, apply Optical Character Recognition (OCR) to extract the text. *Crucially, review OCR quality* – errors here will directly impact the AI's understanding ([SearchBlox, 2024](https://medium.com/searchblox/how-to-process-documents-for-rag-retrieval-augmented-generation-chatbots-616c18e70a85)).
- **[ ] Remove Unwanted Elements:** Clean documents by removing irrelevant headers, footers, page numbers, extensive boilerplate text, or navigation menus (from web scrapes) that don't add semantic value for retrieval ([lakeFS, 2024](https://lakefs.io/blog/data-preprocessing-in-machine-learning/)).
- **[ ] Address Complex Layouts:** For documents with tables, multi-column layouts, or complex figures, consider specialized parsing tools or strategies. Basic text extraction might jumble the content, harming retrieval. Sometimes, converting tables to Markdown or describing figures in text can help ([Akash, 2024](https://akash97715.medium.com/data-preparation-for-rag-part-1-b8bee1130115)).
- **[ ] Check Character Encoding:** Ensure all text uses consistent encoding (UTF-8 is standard) to avoid processing errors.
**Phase 3: Structuring & Chunking Strategy**
- **[ ] Define Metadata:** Identify useful metadata for each document (e.g., title, author, creation date, last updated date, source URL, department, product associated). This metadata can be stored alongside the text chunks and used for filtering during retrieval ([Snowflake, 2024](https://www.snowflake.com/en/blog/streamline-rag-document-preprocessing/)).
- **[ ] Determine Optimal Chunk Size:** This is critical and often requires experimentation. Chunks need to be small enough to be semantically focused but large enough to contain sufficient context. Common sizes range from 100 to 500 tokens ([TiDB, 2024](https://www.pingcap.com/article/building-a-rag-application-from-scratch-a-beginners-guide/)).
- **[ ] Choose a Chunking Strategy:**
- *Fixed Size:* Simple, but can split sentences or ideas awkwardly.
- *Sentence-Based:* Better semantic coherence (e.g., using libraries like NLTK or spaCy).
- *Recursive Character Text Splitting:* A common LangChain technique that tries to keep paragraphs/sentences together.
- *Content-Aware:* More advanced methods that chunk based on document structure (headings, sections) ([Vipra Singh, 2024](https://medium.com/%40vipra_singh/building-llm-applications-data-preparation-part-2-b7306d224245)).
- **[ ] Consider Chunk Overlap:** Overlapping chunks (e.g., sharing a sentence or two at the boundaries) can help ensure context isn't lost at the split points, potentially improving retrieval ([Big Cloud Country, 2024](https://www.bigcloudcountry.com/engineering-blog/planning-checklist-for-rag-projects-retrieval-augmented-generation)).
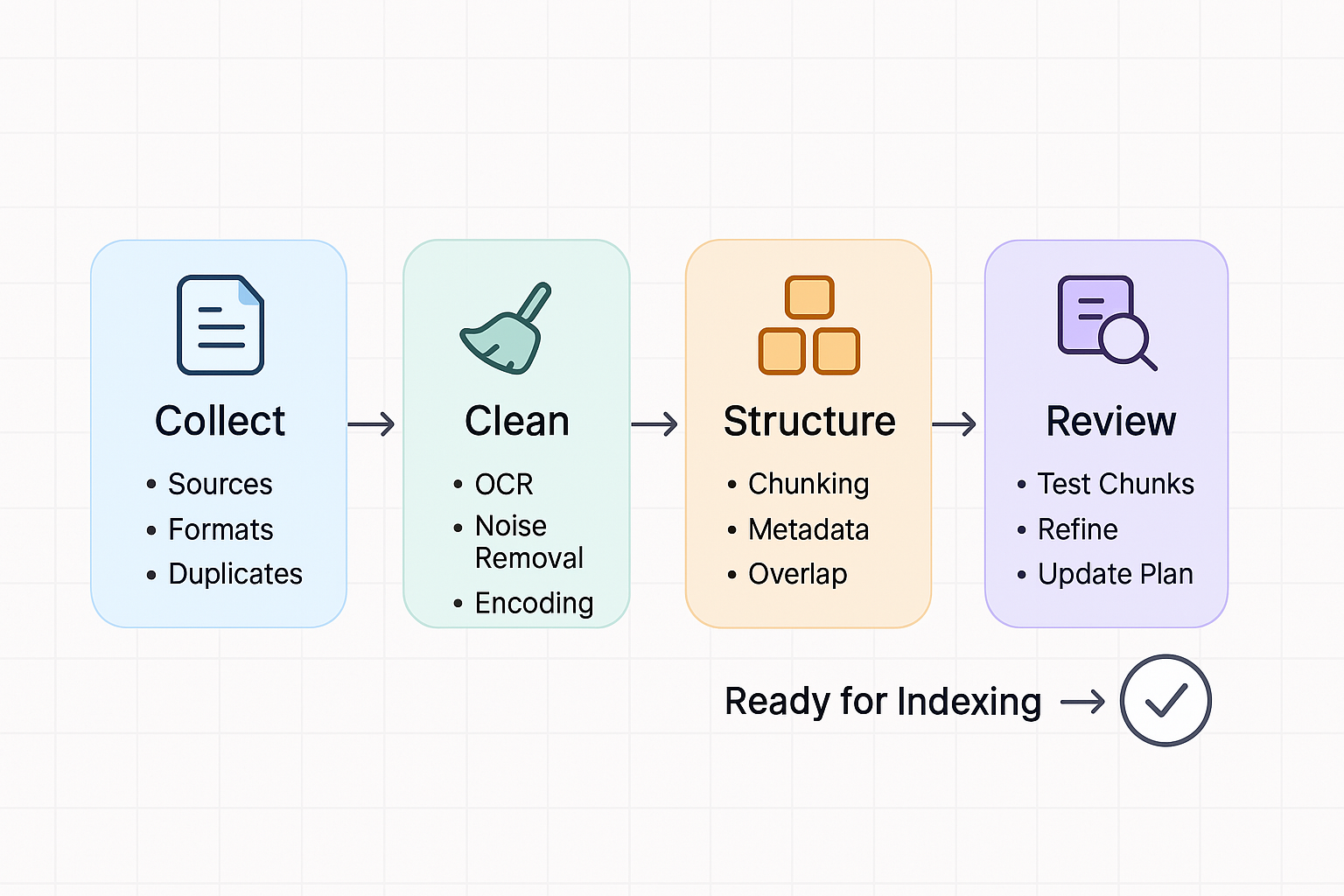
**Phase 4: Review & Iteration**
- **[ ] Spot-Check Processed Chunks:** Before indexing everything, review a sample of the processed text chunks. Do they make sense? Is important context preserved? Is irrelevant noise removed?
- **[ ] Test Retrieval:** Index a subset of documents and test retrieval with representative questions. Are the most relevant chunks being returned? If not, revisit your cleaning and chunking strategy ([GPT-Trainer, 2025](https://gpt-trainer.com/blog/best%2Bpractices%2Bfor%2Bpreparing%2Btraining%2Bdata%2Bfor%2Brag)).
- **[ ] Plan for Updates:** How will new or updated documents be added to the system? Define a process for ongoing maintenance and re-indexing ([Keith Kueh, 2024](https://www.linkedin.com/pulse/best-practices-preparing-private-documents-retrieval-augmented-kueh-pbawc)).
Why This Matters
Thorough data preparation ensures:
- **Higher Retrieval Accuracy:** The system finds the *right* information.
- **More Relevant Answers:** The LLM receives clean, focused context.
- **Reduced Hallucinations:** Less irrelevant noise confusing the LLM.
- **Faster Implementation:** Fewer issues during the indexing and testing phases.
- **Better User Experience:** Users get reliable answers quickly.
Need Help Getting Your Data Ready?
Data preparation can be time-consuming but is essential for RAG success. Fanktank assists clients not only in building the AI system but also in strategizing and executing the crucial data preparation phase.
**If you're considering a RAG system but are unsure about preparing your data, let's discuss how we can help.**
[Book a Free Data Assessment Chat](/contact)
References
- [Snowflake, 2024] ["Streamline RAG with New Document Preprocessing Features"](https://www.snowflake.com/en/blog/streamline-rag-document-preprocessing/), Snowflake. *(Covers best practices for converting and preparing documents for chunking and indexing.)*
- [Akash, 2024] ["Data Preparation for RAG - Part 1"](https://akash97715.medium.com/data-preparation-for-rag-part-1-b8bee1130115), Medium. *(Describes the importance of document standardization and ingestion pipelines.)*
- [Big Cloud Country, 2024] ["Planning Checklist for RAG Projects"](https://www.bigcloudcountry.com/engineering-blog/planning-checklist-for-rag-projects-retrieval-augmented-generation), Rob Whelan. *(Provides a practical checklist covering chunking, metadata, and implementation.)*
- [Keith Kueh, 2024] ["Best Practices for Preparing Private Documents for RAG"](https://www.linkedin.com/pulse/best-practices-preparing-private-documents-retrieval-augmented-kueh-pbawc), LinkedIn. *(Outlines steps for responsible document processing.)*
- [Intel, 2024] ["Four Data Cleaning Techniques to Improve LLM Performance"](https://medium.com/intel-tech/four-data-cleaning-techniques-to-improve-large-language-model-llm-performance-77bee9003625), Medium. *(Focuses on eliminating noise and inconsistencies before ingestion.)*
- [Encord, 2023] ["Mastering Data Cleaning & Preprocessing"](https://encord.com/blog/data-cleaning-data-preprocessing/), Encord. *(Explains foundational cleaning processes for structured and unstructured data.)*
- [deepset, 2024] ["The Role of Preprocessing in RAG"](https://www.deepset.ai/blog/preprocessing-rag), deepset. *(Discusses key preprocessing tasks such as cleaning, chunking, and enrichment.)*
- [orkes.io, 2025] ["Best Practices for Production-Scale RAG Systems"](https://orkes.io/blog/rag-best-practices/), Orkes. *(Focuses on maintaining retrieval precision through document formatting.)*
- [lakeFS, 2024] ["Data Preprocessing in ML"](https://lakefs.io/blog/data-preprocessing-in-machine-learning/), lakeFS. *(Lists steps to eliminate redundancy and improve text consistency.)*
- [SearchBlox, 2024] ["How to Process Documents for RAG"](https://medium.com/searchblox/how-to-process-documents-for-rag-retrieval-augmented-generation-chatbots-616c18e70a85), Medium. *(Highlights OCR importance and document structure concerns.)*
- [Vipra Singh, 2024] ["LLM Applications: Data Prep Pt. 2"](https://medium.com/%40vipra_singh/building-llm-applications-data-preparation-part-2-b7306d224245), Medium. *(Explores different chunking strategies and overlap techniques.)*
- [outerbounds, 2023] ["Retrieval-Augmented Generation Guide"](https://outerbounds.com/blog/retrieval-augmented-generation), Outerbounds. *(Gives context on grounding LLMs through document augmentation.)*
- [TiDB, 2024] ["Building a RAG App from Scratch"](https://www.pingcap.com/article/building-a-rag-application-from-scratch-a-beginners-guide/), TiDB. *(Covers document prep, chunking, and deployment workflows.)*
- [GPT-Trainer, 2025] ["Preparing Data for RAG"](https://gpt-trainer.com/blog/best%2Bpractices%2Bfor%2Bpreparing%2Btraining%2Bdata%2Bfor%2Brag), GPT-Trainer. *(Focuses on testing early and iterating based on retrieval performance.)*
- [Microsoft, 2024] ["Azure AI Search Document Preprocessing"](https://learn.microsoft.com/en-us/answers/questions/2034520/azure-ai-search-document-preprocessing), Microsoft. *(Explains methods for splitting long docs into chunks with tools.)*